Hello everyone,
A month ago I created a set of routines for validating character functions, similar to the functions available in the <ctype.h> header of the C standard library.
I tested different Fortran implementations, which can all be found at my GitHub repository: https://github.com/ivan-pi/fortran-ascii
The different approaches I found are
- A direct approach relying on comparison operators (currently available in stdlib):
pure logical function is_alphanum(c)
character(len=1), intent(in) :: c
is_alphanum = (c >= '0' .and. c <= '9') .or. (c >= 'a' .and. c <= 'z') &
.or. (c >= 'A' .and. c <= 'Z')
end function
- Select case statements:
pure logical function is_alphanum(c)
character(len=1), intent(in) :: c
select case(iachar(c))
case (48:57,65:90,97:122) ! A .. Z, 0 .. 9, a .. z
is_alphanum = .true.
case default
is_alphanum = .false.
end select
end function
- Lookup table (this was the most fun to program)
pure logical function is_alpha(c)
character(len=1), intent(in) :: c
is_alpha = btest(table(iachar(c,i8)),2)
end function
- Interfacing to the C standard library (turns out to be slowest)
pure logical function is_alphanum(c)
character(len=1), intent(in) :: c
is_alphanum = isalnum(iachar(c,c_int)) /= 0
end function
There turned out to be measurable differences between the various approaches:
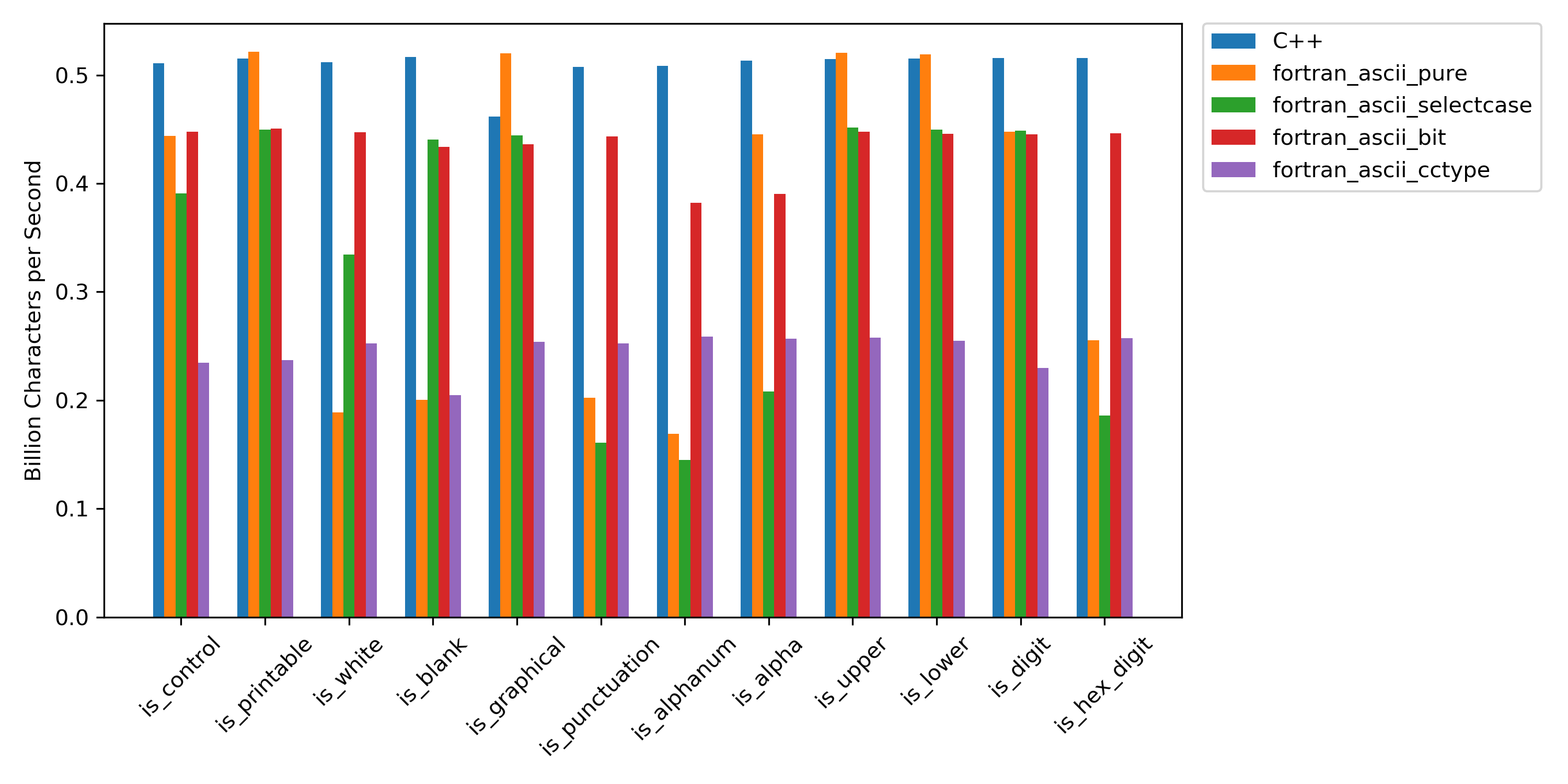
I only tested this with the gfortran compiler. For some of the character validation routines Fortran was able to match C++ or atleast reach 80 % of it’s speed. Since this is essentially a micro-benchmarking problem, there is some uncertainty in the results. I’ve also posted these benchmark results in an issue open at the stdlib repository.
If you have any suggestions or ideas on how to make the Fortran timings more consistent, how to interpret the differences, or how to improve the accuracy of the measurements, please let me know.