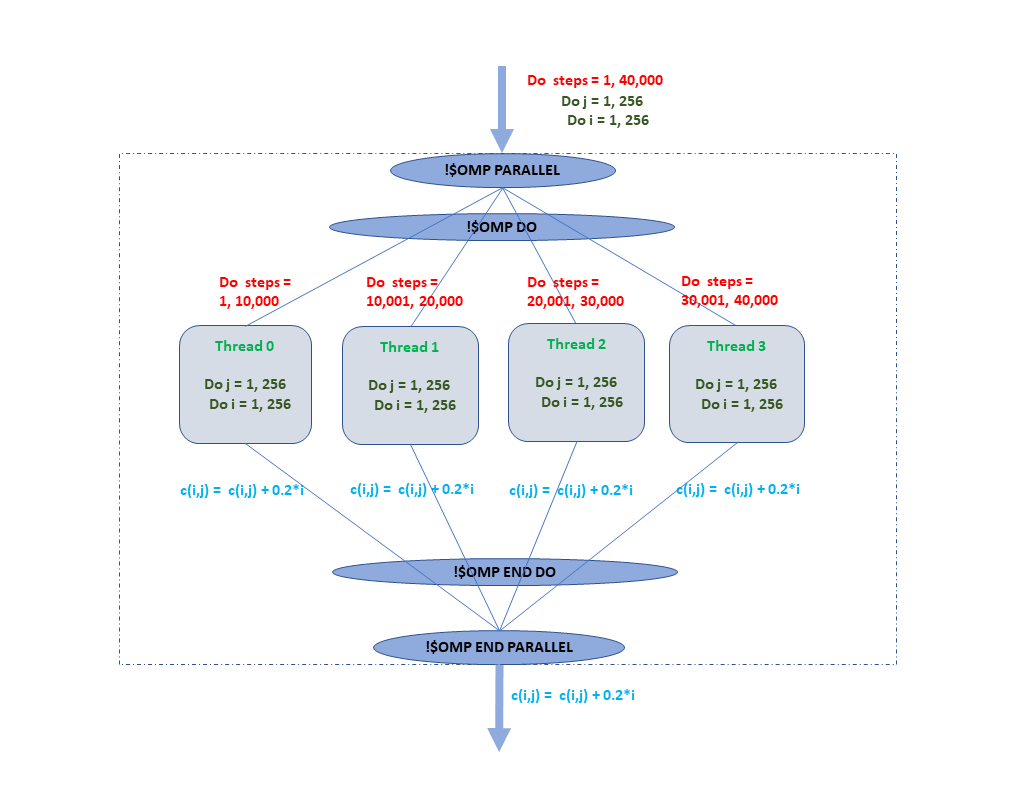
I’m writing subroutine to calculate Laplacian operator:
subroutine laplacian(nx, ny, var, dx, dy, lap)
use omp_lib
implicit none
integer, intent(in) :: nx, ny
real*8, intent(in) :: var(nx, ny)
real*8, intent(in) :: dx, dy
real*8, intent(out) :: lap(nx,ny)
integer :: i, j, ip1, im1, jp1, jm1
real*8 :: start_time, end_time
start_time = omp_get_wtime()
!$omp parallel do default(none) shared(lap, var, dx, dy, nx, ny) private(j, i, ip1, im1, jp1, jm1)
do j = 1, ny
do i = 1, nx
ip1 = mod(i+1, nx)
im1 = mod(i+nx-2, nx) + 1
jp1 = mod(j+1, ny)
jm1 = mod(j+ny-2, ny) + 1
lap(i,j) = (var(ip1,j) - 2*var(i,j) + var(im1,j)) / (dx*dx) &
+ (var(i,jp1) - 2*var(i,j) + var(i,jm1)) / (dy*dy)
end do
end do
!$omp end parallel do
end_time = omp_get_wtime()
write(*,*) "finish computation in ", end_time-start_time, " seconds"
return
end subroutine laplacian
I try to reach higher performance so I also use OpenMP. But I found that the performance is reduced after using OpenMP.
More precisely, the OpenMP version of subroutine will only faster when (nx, ny) is greater than (2000, 2000):
nx=ny=200:
With / Without OpenMP -> 0.0139 / 0.00303 sec
nx=ny=2000:
With / Without OpenMP -> 0.0180 / 0.0719 sec
I only have came up with two possible reasons,
(1) the problem is too simple so that the overhead of creating and managing threads is relatively expensive,
(2) false sharing.
I’m not sure if there will occur false sharing in my subroutine, but I think that it will not. Also I don’t think that the problem is too simple to accelerate by OpenMP. Is there any suggestion that why OpenMP fails? Thanks!