I have a simulator that I have been developing for 15 years now. It’s used for research and some industrial work. Traditionally, I have been using the Intel Fortran compiler with MKL. Recently I decided to give GNU a try since I was asked by a user (he has a MAC and Intel dropped Mac support).
The software makes extensive use of dgetr/dgetrs from LAPACK and an external sparse solver (SuiteSparse KLU). It allows the user to parallelize the computations of dgetrf/dgetrs (there are hundreds of calls to different matrices) by setting the number of threads.
I compile the Intel one with: -O2 -fpp -qopenmp Then, I link to MKL -lmkl_rt
I compile the gfortran one with: -O2 -cpp -fopenmp Then, I link to openblas with -lopenblas
The sequential execution, is already 1.7 times slower for GNU VS Intel. If I dare ask for multithreading, Intel becomes faster with Gnu slower. Everything in the code is the same. I’ve tried this on Windows using MSYS2 and Intel 2024.2 and on Linux Mint with the same versions. Similarly, same performance.
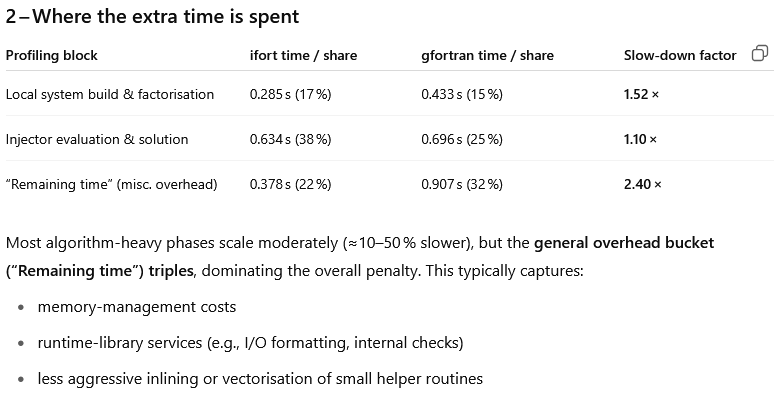
How did you install/build OpenBLAS? The slow-down in “local system build & factorizarion” could probably be attributed to differences in the LAPACK routines. For MacOS it might be worth linking with the Apple Accelerate library instead (with gfortran you just have to add -framework Accelerate).
A slow-down from 1.6 to 2.8 seconds, doesn’t seem like the end of the world. I imagine your true computations are much bigger than this?
I believe that the difference is due to the math libraries not exactly the GNU compilers. If you want to find out the reason you could use a profiler to find which routines are taking the longest time and I’d bet you’d see the difference.
As @ivanpribec suggested, linking to the apple math libraries would be great. He has done some benchmarks that show they’re very nice
For the openblas, I use the libraries “shipped” with MSYS2 or the Linux Mint repo. I did not compile from scratch.
This simulation is part of a sequential decision making algorithm. That is, a python script calls this executable 500-1000 times. So, 1.2 seconds difference times 500-1000 gives a significant difference.
Nevertheless, I was more shocked by the slowdown when multithreading is used.
I’ll try the trick with the Mac but I don’t own a mac, so the user will have to do it.
On the mac, you will find that -framework Accelerate is much faster than -lopenblas, however, I think you lose some fine control over the multithreading behavior because the apple library does some of its own multithreading internally.
Also, if you need to use some of the single precision blas functions, the apple library has some of the common precision errors that occur in many blas libraries. The openblas library on the Mac does NOT have these errors. This is discussed here. How many BLAS libraries have this error? There is a workaround for these errors, so that is another option. Apple has been notified of these library errors, several years ago now, but I think they still persist because the library test suite also has the error, so if you just correct the error in the library, it appears to fail the tests. One must also correct the test code together with the library code. We all have the K&R C compiler convention to thank for this decades long programmer mess.
I am not sure of the build history for your libraries, but for my multi-threaded solvers using Gfortran, I include “-O3 -march=native -fopenmp” which can reliably improve performance for my computation.
I also use “-ffast-math -fstack-arrays” although where multi-threading is not effective, these may have marginal effect.
I have also removed “hyper-threading” for cases of poor OMP efficiency. You could also experiment with fewer threads as it appears that your computation is limited by memory bandwidth or cache size, both of which are dependent on hardware rather than compiler options.
Did you do the different tests on the same hardware or is it compiler and hardware linked tests ? Memory bandwidth and cache size are significant where poor threading efficiency occurs.
Multi-threading does have significant startup overheads (~10,000 processor cycles) so lots of small !$OMP regions can be ineffective. Intel was better than Gfortran for this when I tested years ago, but tuning these types of problems can always change. (Possibly exclude small computation load loops from !$OMP?)
Using multiple hardware options is also challenging where mutti-threading is as ineffective as you are reporting.