A while ago, I compiled a list of all Fortran 2018 keywords from the text of the latest standard (including all specifiers/procedure argument names), to improve Doxygen’s Fortran parser. I have uploaded the list to this GitHub repository just in case others find it useful for similar purposes.
This looks really useful. Question: how much more has to be done to Doxygen before it handles modules and submodules “correctly”?
Thanks. For our documentation needs, I improved a fork of Doxygen a while ago. I have been meaning to announce it in this forum for the use of others too. This branch recognizes the full Fortran 2018 syntax. Here is an example.
I did not feel the need for submodule support beyond syntax recognition (which is automatically done by this branch) because submodules typically contain implementation details, and anything inside them is practically inaccessible to outside units and users. Doxygen (including the main branch) handles modules very well, as far as I know. Do you have a specific module/submodule use-case/example with which Doxygen fails?
2 Likes
Thanks for the effort. I have recently checked doxygen and was suprised by the work and improvements. Having case-sensitivity is essential for readability.
However, I also noticed the call graph issues mentioned in Revives Fortran case-sensitivity + full Fortran 2018 syntax highlighting by shahmoradi · Pull Request #8774 · doxygen/doxygen · GitHub
Furthermore call(er) graphs for type-bound procedure are missing completely. Any reason for that.
And finally, as you specifically ask, excluding submodules excludes a lot of data. For example, we have some submodules with high level subroutines (originally one big spaghetti subroutine, now somewhat refactored into smaller subroutines), with lots of dependencies. The main entrance is still visible, but without the whole call(er) graphs, subtasks and their dependencies to other (sub)modules, a lot is missing. Essentially all the meat, where most of the development work is done, is missing from doxygen.
@shahmoradi Wow! This does look like a step forward, well done. I would echo @martin 's comment about case sensitivity, I am not the only Fortranner who likes to use upper case for the module name and lower case for the specific procedures, e.g.
module WHAM
...
contains
subroutine WHAM_bam
...
end subroutine WHAM_bam
end module WHAM
I admit I have not used repositories very much, so can I ask: is your fork merged back and is now part of the main download for Doxygen or do I have to seek out and use your fork specifically?
Then I can get to work on your question about specific examples
Thank you so much
Thank @NormanKirkby @martin. I understand your concerns, which resemble those of Doxygen maintainers. The main branch of Doxygen currently lowers the case of all Fortran names (modules, subroutines, functions, anything) because Fortran is case-insensitive while the hyperlinking requires case sensitivity. As long as the labels are all snake-case, this is fine. But that is not a neat solution for CamelCase code (I use it everywhere), making the documentation effectively unreadable.
One way to fix this is to ask the Fortran user to preserve case sensitivity in their coding and modify Doxygen to respect Fortran’s case sensitivity, too, as I did in the branch.
The other more fundamental way seems to be too much work I have not had any time yet.
So, in the end, as long as the Fortran user agrees to preserve case sensitivity, all call graphs and documentation links will work just fine. There are no call graphs in the example documentation because I have switched that option off in the configuration file for this particular documentation. Otherwise, they will be generated as expected.
Regarding @NormanKirkby’s concern with mixed cases, there is no problem with it, as long as the case sensitivity is respected wherever needed in the code (to generate the call graphs and links correctly).
@martin @NormanKirkby I committed an update to the Doxygen fork today that resolves the self-reference bug that had remained out of my sight until yesterday reported by rajeeja on GitHub. The call graphs now look correct (as long as case sensitivity is respected in the codebase). Here is an example.
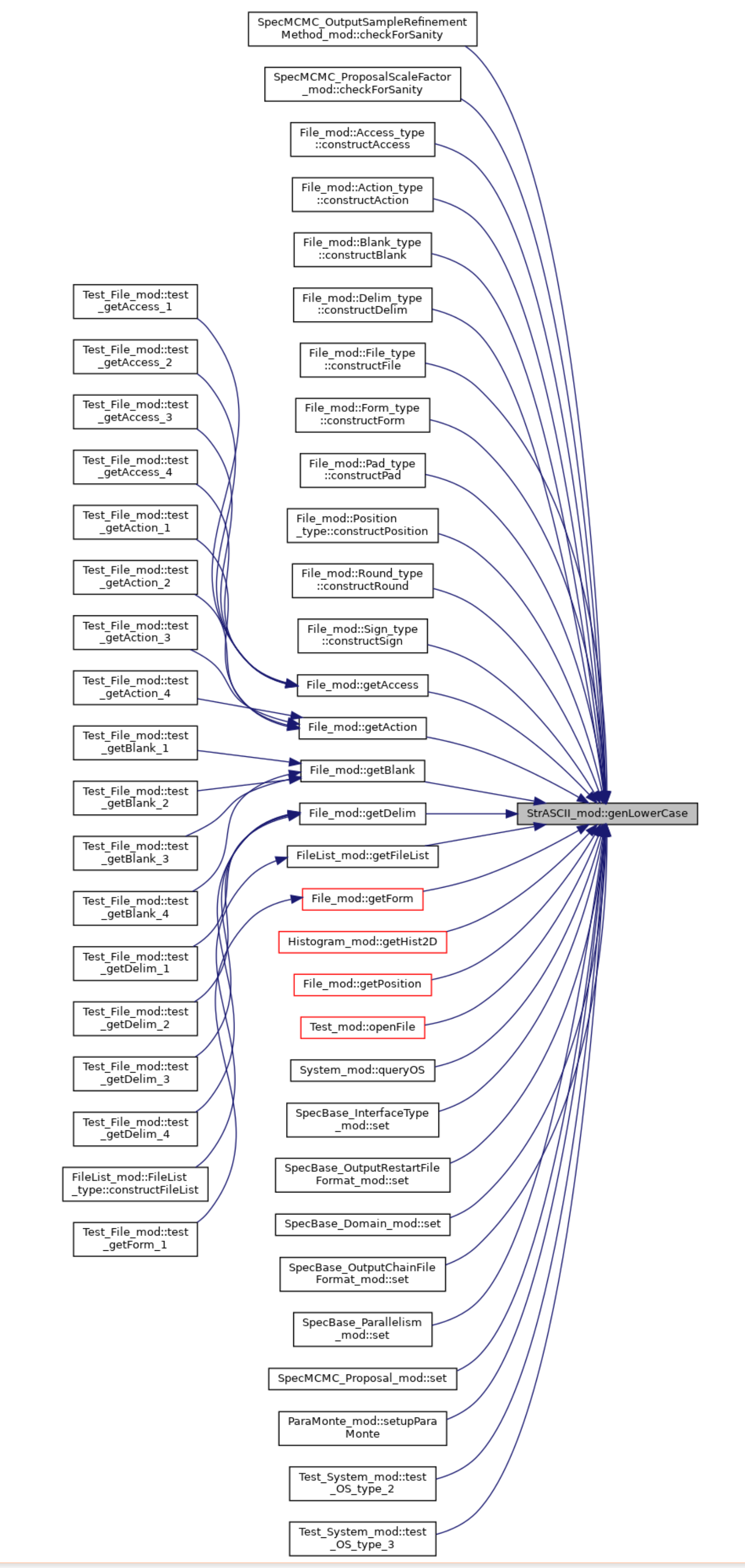{kind=link}
Regarding @NormanKirkby installation question: This fork is not part of the Doxygen main branch. To install and use the fork on UNIX systems,
sudo apt install flex
sudo apt install bison
git clone https://github.com/cdslaborg/doxygen.git
cd doxygen/
mkdir build && cd build
cmake -G "Unix Makefiles" ..
make
In addition to flex and bison, the GNU tools libiconv and GNU make and CMake are also needed.
CMake will generate the binary in ./bin/doxygen relative to the root directory of the Git project. To generate docs with the fork version instead of the local Doxygen installation, simply call the fork’s binary in ./bin/doxygen. That’s all (. An extra last installation step, make install, can put the binary in /usr/local/bin, but I avoid it).
The issue of submodules remains unresolved in this fork. This is the last remaining major issue with Doxygen for modern Fortran in this fork. If someone can volunteer to fix it, I’d be more than happy to help and catalyze the fix. Unfortunately, as of today, I don’t see any opportunity timewise to do it by myself in 2022.
1 Like